
도커 컨테이너 진입
docker exec -it elasticsearch /bin/bash
설치 명령어 입력
bin/elasticsearch-plugin install analysis-nori
Nori
한국어 형태소 분석기
nori_tokenizer
standard 토크나이저와 비교
공백만 분리됨
GET _analyze
{
"tokenizer": "standard",
"text": [
"nori_tokenizer는 명사, 동사, 형용사 등 다양한 품사를 구분하여 토큰화합니다."
]
}
nori_tokenizer
형태소까지 분리됨
GET _analyze
{
"tokenizer": "nori_tokenizer",
"text": [
"nori_tokenizer는 명사, 동사, 형용사 등 다양한 품사를 구분하여 토큰화합니다."
]
}
옵션
user_dictionary
사용자 사전이 저장된 파일 경로 지정
config 디렉토리 상대 경로 작성
사용자 사전이 변경됐다면 인덱스를 _close/_open 해서 반영 시켜야함
기본적으로 사전의 단어들에 우선순위가 적용되어 반영되지만, 사용자 사전에 등록된 단어가 있다면 그 단어가 최우선순위로 반영됨
user_dictionary_rules
사용자 정의 사전을 배열로 입력
기본적으로 사전의 단어들에 우선순위가 적용되어 반영되지만, 사용자 사전에 등록된 단어가 있다면 그 단어가 최우선순위로 반영됨
PUT nori인덱스
{
"settings": {
"analysis": {
"tokenizer": {
"sky_nori_tokenizer": {
"type": "nori_tokenizer",
"user_dictionary_rules": [
"용사"
]
}
}
}
}
}

decompound_mod
합성어 저장 방식 결정
모드를 다르게 하여 토크나이저 저장
PUT nori인덱스
{
"settings": {
"analysis": {
"tokenizer": {
"none_nori_tokenizer": {
"type": "nori_tokenizer",
"decompound_mode": "none"
},
"discard_nori_tokenizer": {
"type": "nori_tokenizer",
"decompound_mode": "discard"
},
"mixed_nori_tokenizer": {
"type": "nori_tokenizer",
"decompound_mode": "mixed"
}
}
}
}
}
none: 어근 분리없이 완성된 합성어만 저장
GET nori인덱스/_analyze
{
"tokenizer": "none_nori_tokenizer",
"text": [ "꽃사슴이다!" ]
}
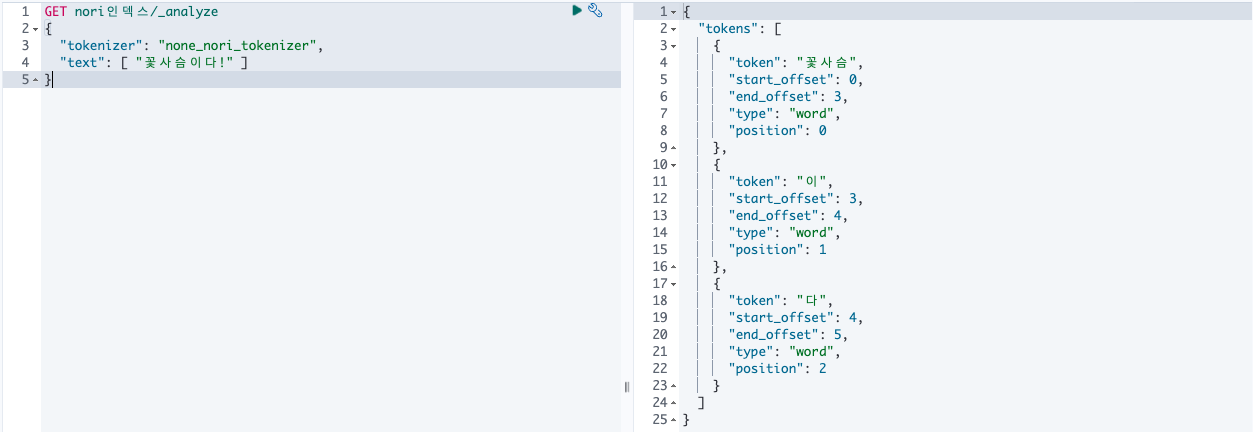
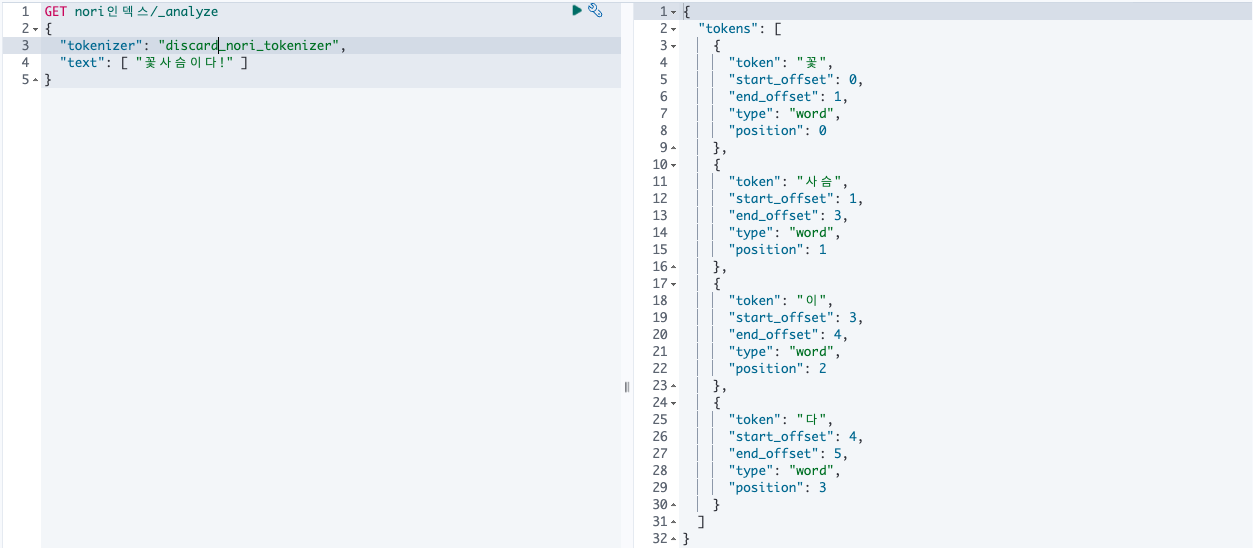
discard: 합성어를 분리하여 각 어근만 저장(default)
GET nori인덱스/_analyze
{
"tokenizer": "discard_nori_tokenizer",
"text": [ "꽃사슴이다!" ]
}
mixed: 어근과 합성어 모두 저장
GET nori인덱스/_analyze
{
"tokenizer": "mixed_nori_tokenizer",
"text": [ "꽃사슴이다!" ]
}

토큰 필터
nori_part_of_speech
제거할 품사(POS: Part OF Speech) 정보 지정
옵션 stoptage 값에 배열로 제외할 품사 코드를 나열해서 입력
지원되는 태그 목록과 의미 확인 하기 👉🏻 품사 태그
"stoptags" : [ "E" , "IC" , "J" , "MAG" , "MAJ" , "MM" , "SP" , "SSC" , "SSO" , "SC" , "SE" , " XPN" , "XSA" , "XSN" , "XSV" , "UNA" , "NA" , "VSV" ]
PUT nori_filter
{
"settings": {
"index": {
"analysis": {
"filter": {
"my_posfilter": {
"type": "nori_part_of_speech",
"stoptags": [
"NR"
]
}
}
}
}
}
}
GET nori_filter/_analyze
{
"tokenizer": "nori_tokenizer",
"filter": [
"my_posfilter"
],
"text": "백설공주와 일곱 난쟁이"
}
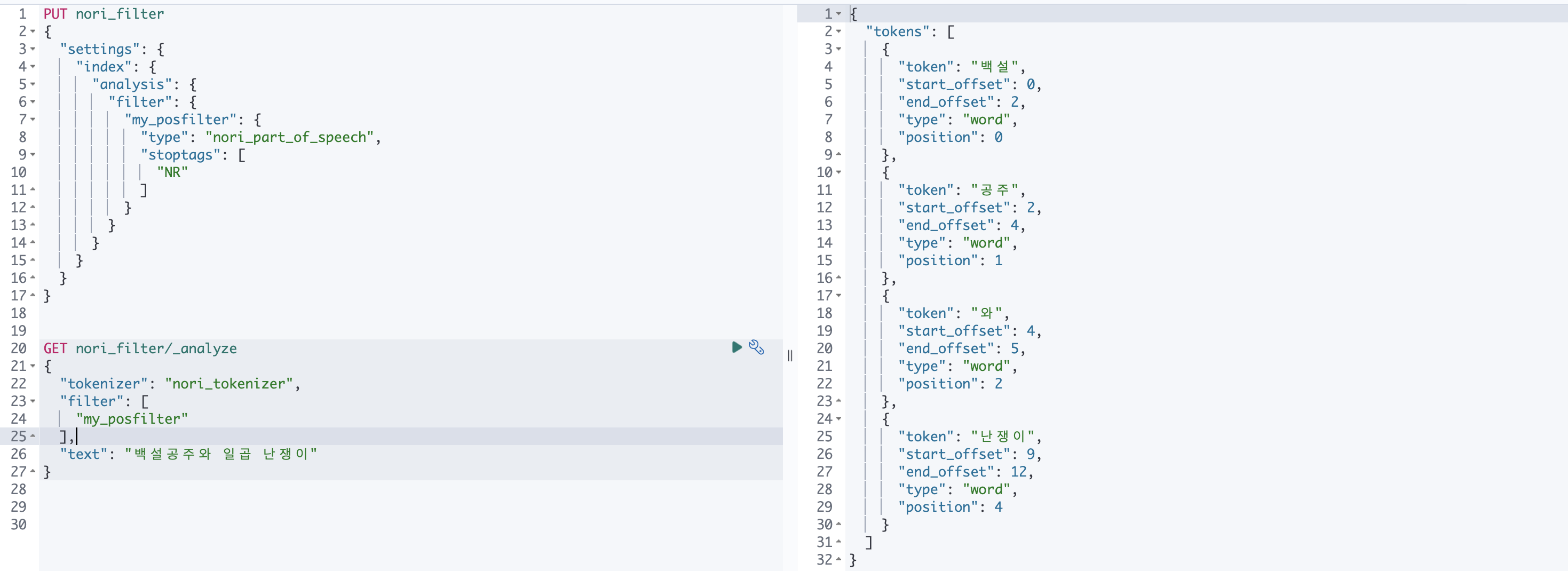
nori_readingform
한자로 작성된 토큰을 한글 형식으로 다시 작성
GET _analyze
{
"tokenizer": "nori_tokenizer",
"filter": [
"nori_readingform"
],
"text": "靑出於藍"
}

nori_number
한국어 숫자를 반각 문자의 일반 아라비아 십진수로 정규화
nori_tokenizer의 Discard_Puntation이 false로 설정되어 있어야 함
표준화된 숫자의 일부가 아닌 구두점 문자를 인덱스에서 제거하기 위해서는 nori_number뒤에 제거하려는 구두점이 포함된 중지 토큰 필터를 추가
PUT nori_number
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "tokenizer_discard_puncuation_false",
"filter": [
"part_of_speech_stop_sp", "nori_number"
]
}
},
"tokenizer": {
"tokenizer_discard_puncuation_false": {
"type": "nori_tokenizer",
"discard_punctuation": "false"
}
},
"filter": {
"part_of_speech_stop_sp": {
"type": "nori_part_of_speech",
"stoptags": ["SP"]
}
}
}
}
}
}
GET /nori_sample/_analyze?pretty
{
"analyzer": "my_analyzer",
"text": "십만이천오백과 3.2천"
}

nori 공식가이드
https://www.elastic.co/guide/en/elasticsearch/plugins/current/analysis-nori.html
Korean (nori) analysis plugin | Elasticsearch Plugins and Integrations [8.12] | Elastic
Korean (nori) analysis pluginedit The Korean (nori) Analysis plugin integrates Lucene nori analysis module into elasticsearch. It uses the mecab-ko-dic dictionary to perform morphological analysis of Korean texts. Installationedit This plugin can be instal
www.elastic.co